
L’objectif principal d’une solution IoT est de transformer des données brutes en informations valorisables. Ces insights créent de la valeur soit en améliorant la productivité de l’entreprise soit parce qu’ils sont commercialisables.
Si les étapes précédentes de l’architecture IoT, qui consistent à capter puis remonter les données, sont primordiales, celles du traitement de la donnée l’est encore davantage. A la manière dont du pétrole brut va être transformé dans une raffinerie, les datas vont être disséquées, analysées, mélangées pour en extraire leur valeur.

Le cycle de vie d’une data : le data pipeline
Comme le serait une matière première dans n’importe quel cycle de production industrielle, la data va cheminer dans un pipeline pour devenir exploitable. Ce pipeline peut être décomposé en quatre étapes successives : la génération, le stockage, la transformation et la valorisation.
Pour illustrer notre propos, nous prendrons l’exemple de données issues d’un ascenseur connecté.
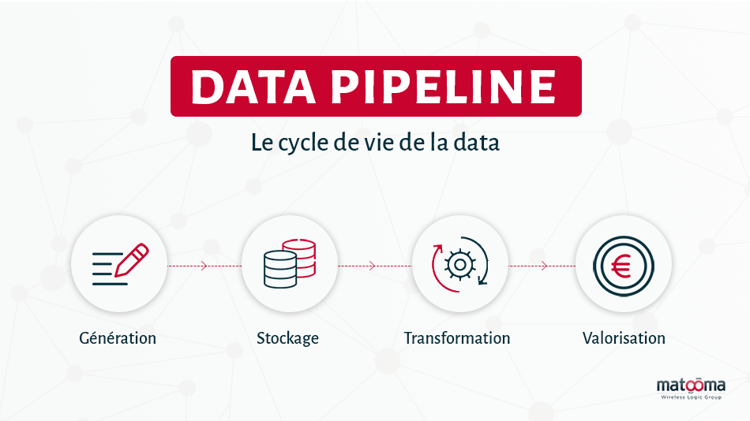
1. Génération
Les datas sont générées par les capteurs IoT qui vont, par l’intermédiaire d’une gateway, les transmettre sur le réseau. Elles peuvent également avoir d’autres sources : base de données, CRM, données topographiques, etc.
A ce stade, ces données brutes, extraites du monde physique, ne sont pas utilisables en l’état. Leur lecture ne ferait aucun sens.
Dans notre exemple, les capteurs installés dans l’ascenseur communiquent la fréquence d’utilisation, les étages les plus fréquemment visités, le nombre de personnes (le poids calculé), la vitesse de l’ascenseur, les avaries plus le flux vidéo de la caméra de sécurité et l'utilisation de l’appel d’urgence.
2. Stockage
Les données générées par les capteurs vont être stockées, pour des durées variables selon le type de data, sur des serveurs géographiquement proches des capteurs.
Il est en effet inutile et coûteux d’envoyer la totalité des données brutes sur le Cloud. Une partie des données peut être conservée et même analysée localement, c’est ce que l’on appelle l'Edge Computing.
Dans notre exemple, les fichiers vidéo de la caméra de sécurité de l’ascenseur sont stockés sur un serveur situé dans le bâtiment, et automatiquement supprimés après une semaine. Pour des raisons de confidentialité et de coût, ils ne sont en aucun cas transmis sur Internet. Le reste des données, ne pesant que quelques octets par jour, est lui transmis en totalité sur le Cloud pour analyse au département Data de la société ascensoriste.
3. Transformation
C’est ici que la magie s’opère. Par une série d’opérations informatiques, les données vont être assemblées, dissociées, passées au crible des algorithmes pour en extraire des informations valorisables pour la société ou ses clients.
Pour cette société d’ascenseur, il s’agit d’identifier dans cette masse de données les signes d’une potentielle avarie avant qu’elle ne se produise. Pour cela, elle doit repérer des patterns, des éléments cachés dans les données qui sont les signes avant-coureurs d’une panne.
4. Valorisation
Les opérations de maintenance prédictive effectuées sur les ascenseurs durant le week-end ont permis de réduire considérablement les interruptions de service pour les clients de notre société ascensoriste. Elle peut commander les pièces à l’avance et réduire ses budgets de fonctionnement ainsi que les astreintes de ses équipes d’urgence.
Là réside la valeur principale d’une solution IoT, en pouvant, grâce à la data, à la fois améliorer ses services et réduire ses coûts.
A quel niveau faut-il analyser ses données ?
Qu’est ce que le Edge Computing ?
Au sein d’une architecture IoT classique, les données sont remontées dans leur ensemble sur le Cloud pour être analysées et transformées. Depuis quelques années, notamment grâce aux progrès techniques au niveau du hardware (ordinateurs moins onéreux et plus puissants), il apparaît parfois plus intéressant de traiter ces données localement.
Imaginons une entreprise fabriquant de la peinture, avec plusieurs sites de production disséminés sur des centaines de kilomètres. Si le siège souhaite connaître en temps réel les cadences de production, toute une série de données liées à chaque usine (consommation d’eau, d’électricité, vidéosurveillance) peut être analysée sur place.
L’intérêt du Edge Computing
Traiter les données localement, sans passer par le Cloud, présente plusieurs avantages comme en premier, la vitesse de traitement. La latence s’en trouve réduite quasiment à zéro, ce qui, pour toute une série d’usages, est décisif (machines autonomes, VR/AR, hôpitaux).
Il est aussi moins coûteux et plus flexible de déployer de petites unités d’analyse en Edge qu’un seul énorme data center. Le ticket d’entrée pour ce type d’installation reste hors de portée pour la plupart des PME. De plus, il nécessite une infrastructure réseau colossale pour acheminer les données de l’ensemble des capteurs disséminés sur les différents sites de l’entreprise.
La démultiplication des points d’analyse rend la solution IoT dans son ensemble moins sensible aux failles de sécurité ou avaries techniques de grande ampleur. En effet, si l’un des sites est touché, il est bien plus envisageable de pouvoir le couper, le temps d’une intervention, que l’ensemble du réseau. Une installation en Edge computing améliore la maîtrise des impondérables de l'architecture IoT.
Edge computing VS Cloud computing
Les motivations à choisir le Edge peuvent être liées à la nature, à l'intérêt stratégique ou bien au volume des données en question. Reprenons notre exemple du fabricant de peinture. Si la direction nécessite d’avoir une vue d’ensemble sur la production et la livraison des commandes, pour améliorer sa productivité et son service client ; elle peut déléguer à chaque directeur d’usine la responsabilité d’améliorer les coûts et le fonctionnement de son propre site.

Faire face à l’hétérogénéité des données
Une installation industrielle, disons une usine automobile, remonte d’immenses quantités de données très hétérogènes, et ce sur plusieurs sites. Il est nécessaire de penser en amont une véritable stratégie data pour savoir :
- quelles données méritent d’être captées
- quelles données méritent d’être remontées sur le cloud
- quelles données méritent d’être stockées pour une utilisation future potentielle
Selon la nature de la data, il sera nécessaire de la prétraiter pour la rendre compatible avec d’autres sources de données. Des capteurs sur une machine industrielle et une caméra thermique sont conjointement intéressants s’ils répondent au même timecode. Il sera donc nécessaire de combiner les deux sources de données à travers un programme informatique pour visualiser et comprendre les données.
Certaines données ont une utilité lorsqu’elles sont en temps réel, par exemple une balise géolocalisée sur un camion de livraison - d’autres uniquement sur un temps long, comme des capteurs environnementaux en forêt.

Le challenge du volume de données
Par définition, les données générées par les capteurs IoT s’accumulent sur une architecture réseau qui est, elle, limitée en capacité. Une installation permettant de stocker 10 terabytes de données sera vite saturée avec 1 terabyte supplémentaire uploadé chaque mois.
Nous observons généralement un biais qui consiste à remonter beaucoup plus de données qu’il serait utile, entraînant plusieurs conséquences néfastes :
- une saturation des espaces de stockage
- une impossibilité d’analyser efficacement les données
- une surconsommation des frais de communication
C’est ce que l’on appelle le data overload, pouvant résulter en l’échec du déploiement de la solution IoT et la destruction des données accumulées, leur stockage devenant trop coûteux.
Il convient donc d’effectuer les opérations adéquates pour traiter les données et réduire leur volume. Par exemple, les données d’un compteur de gaz peuvent être compressées en ne gardant qu’une moyenne quotidienne plutôt que les chiffres exacts heure par heure.
Conserver des données pour une éventuelle utilisation future révèle un manque de préparation dans le déploiement de la solution IoT. Chaque donnée captée doit répondre à un objectif précis : optimisation de la productivité, réduction des coûts, amélioration de la relation client.
Vélocité des données
Une question cruciale lors de la définition de la stratégie data consiste à déterminer la fréquence à laquelle la data doit être accessible. Un détecteur de fuite de gaz doit pouvoir communiquer ses données au plus vite, ce qui est moins le cas pour un compteur électrique.
Batch VS streaming
Le batch consiste à traiter de larges volumes de données sur un intervalle défini. Par exemple, chaque soir, les données des panneaux solaires d’un bâtiment sont relevées et analysées.
Le streaming, à la différence du batch, analyse les données en continu et en temps réel.
Le batch est moins onéreux et adapté aux larges volumes de données. Il n’est toutefois pas adapté à nombre de situations qui nécessitent une surveillance continue (sécurité, santé).
Les enjeux de la sécurité des données
Les données doivent faire l’objet d’une politique de sécurité à part entière. Elles peuvent être la cible de vol, de clé d’entrée dans le réseau d’une entreprise ou tout simplement de perte liée à une erreur humaine ou avarie technique.
Il faut ajouter à cela les risques liés à la confidentialité des données, quand celles-ci concernent des personnes physiques (dispositifs médicaux, géolocalisation).
La data fait l’objet de menaces différentes selon sa progression dans le data pipeline.
- au niveau des devices, via leur fragilité; qu’elle soit hardware ou software
- au niveau des gateways, par une carence de mise à jour ou des interruptions de service (qui va impacter l’ensemble des devices connectés à cette gateway)
- au niveau de la connectivité, avec des interceptions des communications
- au niveau du Cloud, par des fragilités des programmes informatiques
- et enfin au niveau de l’application, par des failles sur l'authentification des utilisateurs.
L’impact du type de data sur le choix de la connectivité
Le type, l’hétérogénéité, la vélocité et le volume de data, tous ces facteurs vont venir impacter le choix de la solution IoT, et en particulier de la connectivité.
Si une connectivité LPWAN suffit pour remonter des batch de données techniques (relevés de compteurs, données météo), une connexion cellulaire ou haut débit câblé (fibre) est nécessaire pour des datas en streaming ou volumineuses (flux vidéo).
Avec l’arrivée des réseaux 5G privés, principalement pour des solutions industrielles de grande ampleur, même des réseaux locaux (Edge) peuvent avoir recours à une connectivité cellulaire. Les nouveaux usages (robotique, drones, AR/VR, télémédecine), nécessitant des latences quasi nulles, devront pour répondre à ce challenge technique combiner l'Edge computing et la 5G.
Sources
https://www.thalesgroup.com/en/markets/digital-identity-and-security/iot/iot-security

27 pages de conseils concrets
Pour tout comprendre sur la carte SIM M2M
Télécharger le guide gratuitementNewsletter IoT